My home lab has been getting a bit long in the tooth recently. These days I work mostly with container platforms and Infrastructure as Code but those are mostly put to work inside the opaque walls of public cloud providers and not on bare metal (I.E. my own physical or virtual servers).
When it comes to container platforms, Kubernetes is the one I spend most of my time with. Running anything on bare metal is a good way to gain a better understanding of how it’s various components actually work and usually presents some unique challenges regarding networking and high availability that are pretty fun to solve when there is no cloud provider to do the heavy lifting for you. Kubernetes has proven to have a few of these challenges.
I’m not going to dive in to the basic ins and outs of what Kubernetes actually is and what it’s core components do, those topics have been covered exhaustively by everyone else and it would make these articles impossibly long. I want to stick to the build but I’ll provide links where relevant.
The full code for this post can be found in GitHub here.

What and Why?
I’ve come across dozens of articles that discuss this same topic while working on my builds and as best I can tell they’re mostly all copying from each other, very unhelpful. They often don’t well explain things outside of parroting what the Kubernetes components are, provide an insight in to why things work or offer solutions to the various networking and high availability challenges that working outside of the cloud presents.
If you’re following along, I’m going to assume you have both kubectl and ansible installed. If not, click the links for installation guides for both.
My aim in this project is to deploy a Kubernetes cluster which:
- Runs on virtual servers running on my existing VMware ESXi Host (for as little as possible)
- Is deployed and configured with as much automation as possible (or as much as is useful)
- Provides a platform to run several apps at once full time and have space to run several more
- Can use a local NFS server to manage persistent volumes
- Is highly available and stays up in the event that a VM crashes or needs to be rebooted
- Can run for the long term but doesn’t become a complete nightmare to manage
Roughly, that should look something like:
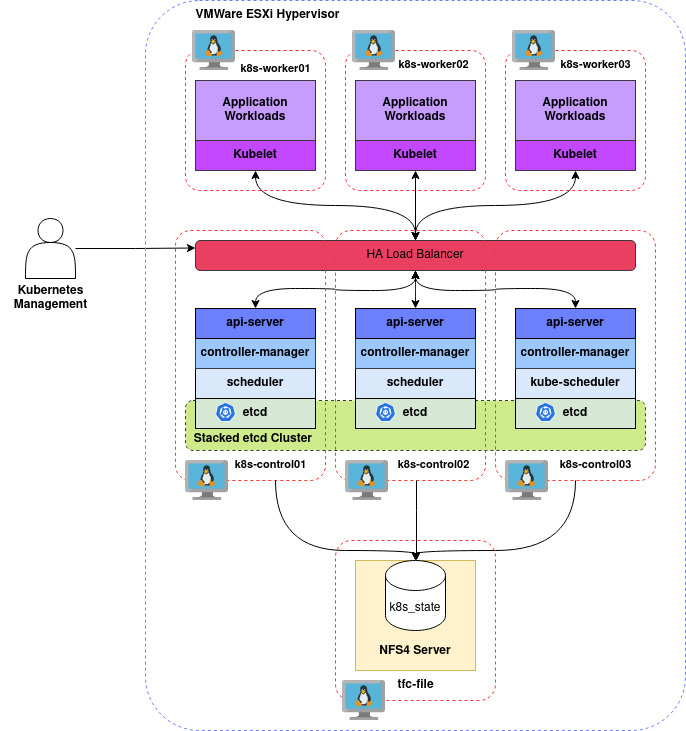
Looks simple on paper, how hard could it be?
Resource Limitations
Building the nodes is a straightforward process in VMware but specification and how we juggle virtual hardware resources is important. With the method we’re going to employ, which will ensure that we can stay highly available and load balance services, we should have at least three Control Plane Nodes to make up the Control Plane and at least three Worker Nodes to make up the Data Plane.
We’re going to allocate our resources as below:
| VM Name | vCPUs | RAM (GB) |
|---|---|---|
| k8s-control01 | 2 | 2 |
| k8s-control02 | 2 | 2 |
| k8s-control03 | 2 | 2 |
| k8s-worker01 | 2 | 4 |
| k8s-worker02 | 2 | 4 |
| k8s-worker03 | 2 | 4 |
Whilst Kubernetes does not enforce a memory requirement, kubeadm (the tool which we’ll using to bootstrap Kubernetes) does by default enforce a minimum of 2GB. To that end, our Control Plane nodes are going to get 2GB each and our Workers are going to get 4GB each.
If you are running on a host with a very limited amount of RAM (like I am) you can squeeze out some more memory still. VMware happily supports Memory Overcommitment but things could go wrong fast under load, so when building our Workers we need to ensure that they are set to Reserve all guest memory on the host, ensuring that they will always have access to the full 4GB at all times:
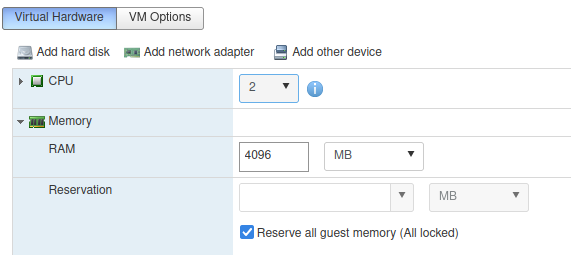
The Control Plane nodes will handle relatively little load in a lab and can be happily left without this configuration (based on my observations their load has not raised much above 1GB for the use they have seen on a home network).
Network Considerations
Before diving in, we will need to think about how we’re to lay the host network out.
The VMs are configured with a single NIC each (ens160) as below:
| Server | Role | IP Address |
|---|---|---|
| k8s-control01 | Control Plane | 192.168.1.200 |
| k8s-control02 | Control Plane | 192.168.1.201 |
| k8s-control03 | Control Plane | 192.168.1.202 |
| k8s-worker01 | Worker | 192.168.1.210 |
| k8s-worker02 | Worker | 192.168.1.211 |
| k8s-worker03 | Worker | 192.168.2.212 |
I have also reserved the following IPs range on my host network for use by Kubernetes:
| Range | Use |
|---|---|
| 192.168.1.220 | Kubernetes API |
| 192.168.1.225-234 | Any Kubernetes LoadBalancers |
- In order to reliably serve the Kubernetes API, we will also be configuring a DNS hostname which resolves to it’s IP address (I’ll be using a bind9 DNS server but in a pinch you can use your hosts file). The hostname I’ll be using is k8s.tinfoilcipher.co.uk, you should use something suitable for your network.
- A fairly large range should be saved for LoadBalancers as these will be used to expose applications which are running inside the cluster when needed.
Finally, we will also need to define a two large, separate subnets used to:
- Serve the Pod Overlay Network (this serves unique IP addresses to Pods)
- Serve the Clusters ClusterIPs for internal Services
It is important to be sure that both of these ranges can provide a large DHCP pool which will not easily exhaust and will not clash with anything on the host network. To make our lives easier, we will be using the defaults for both the Service Range (as used by kubeadm) and our Overlay:
| Subnet | Use |
|---|---|
| 10.96.0.0/12 | ClusterIP Range |
| 10.244.0.0/16 | Flannel Overlay Network |
Chose all of these addresses to suit your own network. Now let’s get the VMs created.
Building the VMs
To get the deployment started we’re going to need to create Virtual Machines in VMware. I won’t go through the process step by step, if you made it here you probably already know how to do that. I’ll be using Ubuntu 22.04.02 (the current latest LTS release at time of writing).
As part of the installation wizard the manual tasks we will need to do are:
- Creating a single local user account named svc_mgmt which will be used for SSH and administrative tasks as we go on
- Installing OpenSSH Server and configuring for key-based authentication only
- Configuring the relevant static IP and hostname for each server
- Create a single 50gb storage volume. We can realistically use much less, the storage should only be needed for caching docker images, but I have the space and why create issues later
Whilst installing the SSH server we can also make use of a useful step added to the Ubuntu installer over the last few versions; the ability to download known public keys from GitHub to our single account’s authorized_keys file. This is particularly useful as we can use this key as our basis for configuring the VMs via Ansible once the installations are complete:
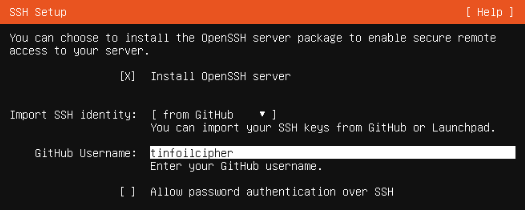
You don’t need to import an identity from GitHub of course, but you’ll need to import your own authorized_keys files to each VM if not.
Prepping Nodes with Ansible
So first, lets get the configurations that we’ll need downloaded:
git clone https://github.com/tinfoilcipher/kubernetes-baremetal-lab.git
Once our nodes have all booted we need to go through the process of configuring them, we could do this manually but Ansible is the perfect tool to get our servers ready for use, I don’t want this system to become an albatross around my neck so let’s automate the builds in case they need to be rebuilt for some reason (that’s already happened to me getting here, so automation is your friend).
There’s a few things I like my baseline Role to ensure for any system:
- Hostname/network configuration is maintained
- Users are managed along with their group memberships
- A strong SSH configuration is defined
- Baseline software packages are installed
- NTP is configured to avoid any time weirdness
On top of these we will need to perform some special tasks specific to Kubernetes:
- Ensure Swap is disabled
- Create a Service Account for Kubernetes called svc_kubernetes
- Create a /home/svc_mgmt/.kube directory for the cluster administrators KUBECONTEXT file
- Install the software packages to bootstrap and manage Kubernetes
- Install the software packages to make a HA loadbalancer for Kubernetes
We can apply all of these if we download and apply the Playbook with:
#-----------------------------------------------------------------------------------------------#
#-- BE SURE TO UPDATE THE BELOW FILES RELEVANT TO YOUR HOSTNAMES/IP ADDRESSES BEFORE RUNNING: --#
#-- inventory.yaml --#
#-- main.yaml --#
#-----------------------------------------------------------------------------------------------#
cd ansible
ansible-playbook -i inventory.yaml main.yaml -K # -K is needed on first run due to prompt for become (sudo) password
# sudo is configured on nodes during the first run.After a bit of a wait and hopefully a lot of green text, our changes will apply and the nodes will all be configured.
Bootstrapping The Control Plane with kubeadm
Our nodes are now up and we can use kubeadm to get Kubernetes up and running. This is where a lot of guides tend to begin and end so lets dig in a bit deeper and break down exactly what we’re going to do and why.
Before we can do anything, we’ll need to get our first Control Plane node ready to go. SSH on to k8s-control01 and execute:
#--Switch to the Kubernetes service account (created by Ansible during build) sudo su svc_kubernetes #--Use Kubeadm to pull base images sudo kubeadm config images pull #--Initialise cluster sudo kubeadm init \ --control-plane-endpoint k8s.tinfoilcipher.co.uk:443 \ --upload-certs \ --pod-network-cidr=10.244.0.0/16
This final command will bootstrap our Kubernetes Cluster (I.E. bring the Kubernetes Control Plane up). This alone is an involved process which involves:
- Setting up a systemd unit for the kubelet
- Using the pre-downloaded images to deploy the Kubernetes core services (kube-apiserver, kube-scheduler, kube-controller-manager and etcd). These are deployed to the native container runtime and then adopted by the created Kubernetes cluster (a very cool method known as a self-hosted bootstrap).
- Creating a self-signed PKI to keep communication between the whole lot encrypted
- Issuing us with a kubeconfig file that we can use to access our cluster at all…
You can see why kubeadm became so popular but it is important to understand exactly what it does when something goes wrong.
Beyond that, what are all these extra arguments that we’re inputting and what do they do? Let’s examine them:
- –control-plane-endpoint k8s.tinfoilcipher.co.uk:443: By Default, kubeadm will set the Kubernetes API endpoint to the IP of the server that you are running on and will use the TCP port 6443. Explicitly specifying a DNS name will allow us to set up a HA load balancer between multiple Control Plane Nodes, we’re also going to run our API explicitly on TCP port 443
- On the localhost, the Kubernetes API will still be served on 6443
- –upload-certs: This exposes the Kubernetes certificates and keys for the Kubernetes and etcd services to a Kubernetes secret for the first two hours of the clusters life. These secrets must be available to other nodes attempting to join the Control Plane.
- –pod-network-cidr=10.244.0.0/16: This is the IP subnet that Pods will use for communication.
After a lengthy execution, we will get a completion message to our terminal along with some further instructions on how to get set up (which we’ll cover in a second):
# Your Kubernetes control-plane has initialized successfully! # ... # [upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace # ... # You should now deploy a pod network to the cluster. # ... # You can now join any number of control-plane nodes by copying certificate authorities # and service account keys on each node and then running the following as root: # # kubeadm join k8s.tinfoilcipher.co.uk:6443 --token da134jgfu\dh023d:2mfdinka \ # --discovery-token-ca-cert-hash sha256:12ee363a45023f9649b3245c243259434592ea3463a49c577123 # --control-plane # # Then you can join any number of worker nodes by running the following on each as root: # # kubeadm join k8s.tinfoilcipher.co.uk:6443 --token da134jgfu\dh023d:2mfdinka \ # --discovery-token-ca-cert-hash sha256:12ee363a45023f9649b3245c243259434592ea3463a49c577123
Make a note of the join commands that are printed, we’ll be needing them to join the rest of our nodes.
Before logging off, we will need to run the following commands to copy the kubeconfig to a suitable location where our management account can access it:
sudo cp /etc/kubernetes/admin.conf /home/svc_mgmt/.kube/config sudo chmod 600 /home/svc_mgmt/.kube/config sudo chown svc_mgmt /home/svc_mgmt/.kube/config
Copying /home/svc_mgmt/.kube/config to your local machine (at ~/.kube/config) will allow you to manage the cluster remotely from this point. This kubeconfig file defines the connection and authentication parameters for your cluster (also known as your Kube Context).
Now we can log off k8s-control01 and finish setting up the rest of the Control Plane.
Making the Control Plane Highly Available
Out of the box, kubeadm won’t make your Control Plane highly available just by adding more Control Plane nodes. Some work needs to be done behind the scenes to make us HA. On top of that, we need to ensure we use a minimum of 3 Control Plane nodes.
If you don’t read the documentation clearly enough you would be forgiven for thinking you could just have two Control Plane nodes with one active and one passive but this isn’t the case, to understand why let’s dig in to how Kubernetes works under the hood. etcd is employed as a distributed value store that allows each Control Plane node to share data with the others. In an ideal world (certainly a production world) we would be employing an external etcd but in our cheap home setup here we’re using a Stacked etcd Cluster (meaning that etcd is installed on each node). etcd uses the Raft algorithm to come to a majority consensus about which Node is currently the “Leader” and requires a minimum of 3 nodes to do this (since 3 is the minimum amount needed to have a majority). Take a look at the etcd FAQ if you enjoy that kind of thing.
But all of that just makes our etcd cluster HA, we still need a way to make our Kubernetes API Highly Available…
Part of our Ansible setup earlier involved setting up haproxy and keepalived on each of our Control Plane nodes. Together these provide a battle tested HA Load Balancing system. This works by combining two services:
- keepalived serves a virtual IP which is bound to the nodes NIC and shares it amongst all nodes. The sharing is authenticated with a shared secret.
- haproxy balances traffic between each of the nodes by accepting connections on TCP/443 and passing them to the Kubernetes API server on TCP/6443 on any of the available Control Plane nodes using a Round Robin distribution method.
Simply, this looks like:
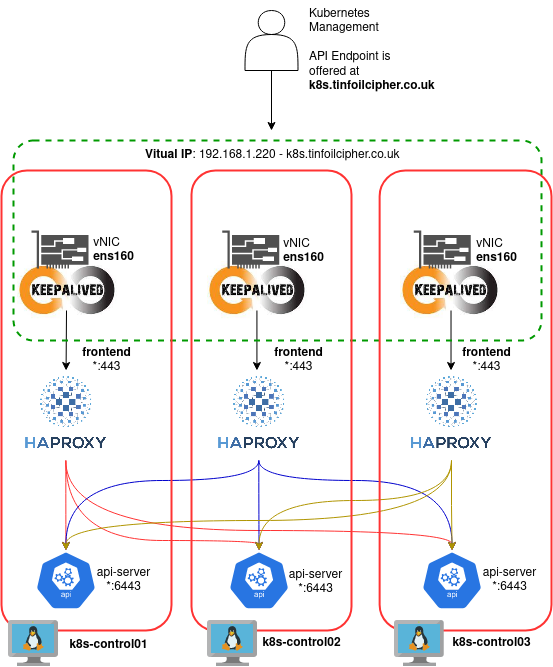
For the avoidance of doubt, this is configured here and here in the Ansible Control Plane Role.
If you’re using the provided Ansible Playbook you get this for free, but it is important to know why it works.
This is all useless unless we add the rest of our Control Plane Nodes to the cluster. SSH to k8s-control02 and run:
#--Switch to Kubernetes service account sudo su svc_kubernetes #--Replace the cluster, token and hash as suitable sudo kubeadm join \ k8s.tinfoilcipher.co.uk:443 \ --control-plane \ --token da134jgfu\dh023d:2mfdinka \ --discovery-token-ca-cert-hash sha256:12ee363a45023f9649b3245c243259434592ea3463a49c577123
After a while the node will join the cluster and you can log off. Then repeat the process on k8s-control03.tinfoilcipher.co.uk.
Finally, we need to label our Control Plane Nodes to ensure that they are all properly marked as part of the Control Plane and are not included when deploying any Kubernetes LoadBalancers:
#--Label Control Plane Nodes
kubectl label node k8s-control01.tinfoilcipher.co.uk node-role.kubernetes.io/control-plane='' \
node.kubernetes.io/exclude-from-external-load-balancers=''
kubectl label node k8s-control02.tinfoilcipher.co.uk node-role.kubernetes.io/control-plane='' \
node.kubernetes.io/exclude-from-external-load-balancers=''
kubectl label node k8s-control03.tinfoilcipher.co.uk node-role.kubernetes.io/control-plane='' \
node.kubernetes.io/exclude-from-external-load-balancers=''As an aside, “load-balancers” here doesn’t refer to our haproxy solution, but to the Kubernetes LoadBalancer Service type. We’ll get back to that in Part 2.
With the Control Plane bootstrapped, we can move on to configuring the network.
Configuring the Overlay Network
If we take a look at our nodes right now, we’ll see that despite proper initialisation…none of them are in a Ready status:
kubectl get no # NAME STATUS ROLES AGE VERSION # k8s-control01.tinfoilcipher.co.uk NotReady control-plane 21m v1.25.0 # k8s-control02.tinfoilcipher.co.uk NotReady control-plane 5m v1.25.0 # k8s-control03.tinfoilcipher.co.uk NotReady control-plane 1m v1.25.0
If we investigate further we will see that the CNI (Container Network Interface) is not yet properly initialised and this is preventing DNS from starting. All very logical. You will have hopefully noticed a console message telling you to deploy a Pod Network, but let’s actually address why that is…
By default, Pods cannot talk to each other when running on different Worker Nodes which somewhat undermines the idea of a distributed system. They will also obtain IP addresses via DHCP from the same network as their hosts which can quickly result in a depleted DHCP pool in a lot of scenarios (and almost certainly on the average home network).
We could solve both of these problems with traditional physical network devices, but a much more common solution these days is to use a Kubernetes CNI Plugin that employs an Overlay Network. This let our Pods act as if they were in one large Layer 2 subnet as well as taking care of DHCP.
For this purpose we’ll be using the Flannel CNI, which takes traffic from within a pod and uses the VXLAN technology for encapsulation. I chose Flannel for no reason other than I have been using it for a while and I know my way around it a little. If you have a network plugin you prefer, use it.
As mentioned already will be using the default subnet configuration for Flannel of 10.244.0.0/16 for the sake of simplicity (a network that we have already defined during our bootstrap process). If you want to use something different feel free.
Again, I won’t dive in to every line but you can see where this is defined here. Apply the overlay configurations to your cluster with:
#--If you are using a different subnet from 10.244.0.0/16, be sure to download and modify this manifest or your pods #--won't be able to communicate! kubectl apply -f kubernetes/flannel_overlay.yaml
With this up and running our nodes will slowly come to life, after a few minutes our nodes should all be talking to each other:
kubectl get no # NAME STATUS ROLES AGE VERSION # k8s-control01.tinfoilcipher.co.uk Ready control-plane 32m v1.25.0 # k8s-control02.tinfoilcipher.co.uk Ready control-plane 16m v1.25.0 # k8s-control03.tinfoilcipher.co.uk Ready control-plane 12m v1.25.0
At the high level, our cluster networking now looks like:
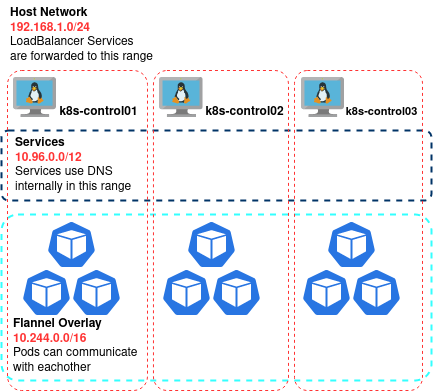
The only pods running on our Control nodes are those responsible for running the core Kubernetes services. This same network model will apply to the Worker Nodes we join next, where all application workloads will be deployed. So let’s add some…
Adding Worker Nodes
Adding the Worker Nodes is a pretty straight forward process, SSH on to each Worker Node (k8s-worker01, k8s-worker02 and k8s-worker03) and execute on each one:
#--Switch to Kubernetes service account
sudo su svc_kubernetes
#--Replace the cluster, token and hash as suitable
sudo kubeadm join k8s.tinfoilcipher.co.uk:6443 --token da134jgfu\dh023d:2mfdinka \
--discovery-token-ca-cert-hash sha256:12ee363a45023f9649b3245c243259434592ea3463a49c577123
After a short wait, each node should join the cluster and is now ready to accept scheduled workloads.
If we take a look at our nodes now, we should have a healthy stable cluster ready to deploy to:
kubectl get no # NAME STATUS ROLES AGE VERSION # k8s-control01.tinfoilcipher.co.uk Ready control-plane 39m v1.25.0 # k8s-control02.tinfoilcipher.co.uk Ready control-plane 23m v1.25.0 # k8s-control03.tinfoilcipher.co.uk Ready control-plane 19m v1.25.0 # k8s-worker01.tinfoilcipher.co.uk Ready 7m v1.25.0 # k8s-worker02.tinfoilcipher.co.uk Ready 5m v1.25.0 # k8s-worker03.tinfoilcipher.co.uk Ready 2m v1.25.0
Next Steps, Deploying Applications
This is all good and well, but a cluster is pretty worthless without any applications running on it.
This article is already long enough though so I’m going to split it in to a couple of parts. In Part 2 I’m going to discuss the various additional network challenges on bare metal, PKI implementation, accessing shared storage and deploying some initial applications.
Hello, I’m giving this a try but getting a couple of errors when running “ansible-playbook -i inventory.yaml main.yaml -K “:
First one was “ERROR! The requested handler ‘restart timesyncd’ was not found in either the main handlers list nor in the listening handlers list” that came up on the ubuntu-baseline : System Baseline Time Config – Ensure timesync Configuration task. I ended up removing the task from ensure-host-config.yaml and manually setting the timezone and NTP servers.
The second came up when the “kubernetes-control : Kubernetes Controller HA – Ensure haproxy.cfg” task ran:
“An exception occurred during task execution. To see the full traceback, use -vvv. The error was: ansible.errors.AnsibleUndefinedVariable: ‘ansible.vars.hostvars.HostVarsVars object’ has no attribute ‘ansible_default_ipv4’. ‘ansible.vars.hostvars.HostVarsVars object’ has no attribute ‘ansible_default_ipv4′”
I see the code on line 53 of haproxy.cfg.j2 but not sure if the variable needs to be set somewhere else.
Also, thanks for this article! I’ve been learning quite a bit!
Thanks! I see the errors, I’ve merged in some fixes that should sort here: https://github.com/tinfoilcipher/kubernetes-baremetal-lab/pull/6