A short while ago I wrote about setting up Continuous Deployment for Terraform using Bitbucket. Whilst that post is perfectly accurate from a technical standpoint it leads us in to a real minefield and really I don’t think it’s a very good idea to use Terraform in Continuous Deployment at all, rather a system of Continuous Delivery is more effective utilising manual deployments. This post is going to look at why and how to achieve that (and if you haven’t read the previous article, please do as this one will be referencing it a lot)!
The simple sample code for this article can be found here.

Continuous Delivery, Deployment? What?
No buzzword seems to be more tossed around that CI/CD Pipelines, Google Trends certainly seems to suggest that the need for knowledge is growing exponentially and you need look no further than any DevOps job spec in the last few years to see that everyone’s asking about it. In my experience nobody seems to really have a solid definition, but let’s get in to that argument on another day.
Compounding the problem is the fact that the CD component of CI/CD can be taken to mean either Continuous Deployment or Continuous Delivery. These terms often seem to be used interchangeably but they’re decidedly different, with Delivery meaning the automatic test and release of an entity and Deployment meaning (as you might expect) the automatic deployment of that entity to some kind of infrastructure.
It’s important to remember that these terms weren’t really made with Infrastructure in mind, they related to the life cycle and and automated release of software artifacts. In an age of Infrastructure as Code and declarative Configuration Management, however these practices are now very appropriate for the creation, testing and management of our cloud environments.
So Where’s The Problem
As mentioned, the solution that we looked at previously was technically fine, but it has a serious risk; as soon as we commit…all changes to the infrastructure will be automatically applied. This can lead to truly awful disasters as even seasoned Terraform operators can make the wrong change and this might lead to you wiping out chunks of a perfectly good live environment.
In a nutshell, our old implementation looks like:
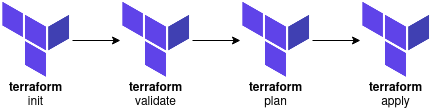
So clearly we need a better approach; one that will let us project our changes using a plan and then, assuming we’re happy with what we see, apply the configuration manually as a final safety gate.
This makes our new implementation look more like:
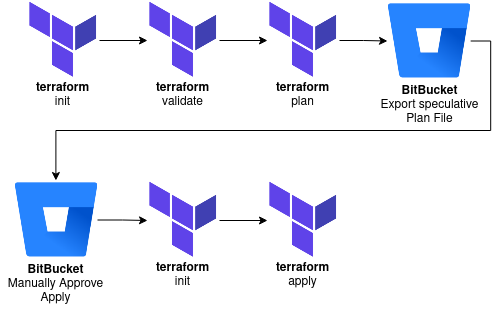
Terraform Plan + Apply != Terraform Apply
The commands we’ll need to run to achieve this configuration are fairly straight forward, but there’s a few added quirks in there so lets break them down and look at how we’ll use them within a pipeline.
#--Initiate Terraform w/Custom AWS Backend Authentication using Environment Variables terraform init -backend-config="access_key=$TF_VAR_AWS_ACCESS_KEY" -backend-config="secret_key=$TF_VAR_AWS_SECRET_KEY" #--Select Terraform Workspace, named after the current git branch. The $BITBUCKET_BRANCH environment variable will #--use a literal string of the branch the commit was made to. #--The or operator (||) is used to create a new workspace if one does not exist terraform workspace select $BITBUCKET_BRANCH || terraform workspace new $BITBUCKET_BRANCH #--Lint the current configuration terraform validate #--Generate a plan and output to a .plan file named for the git commit ID that triggered the pipeline terraform plan -out $BITBUCKET_COMMIT.plan #--Apply the Terraform configuration, using the generated specilative plan as in input source and auto-approving terraform apply -input=false -auto-approve $BITBUCKET_COMMIT.plan
A friend of mine has often joked that plan has no value on it’s own as apply already runs it’s own implicit plan. But as with all things the devil is in the detail, running plan and outputting the results to a file means that the resulting speculative plan can only be used once.
Combined with our solution of creating a plan file named with the the git Commit ID that triggered the pipeline we create an artifact that can only be used to run an apply once, for better or worse. This is a very useful feature and we can build in to our pipeline for free!
Automating With A Pipeline
I’m not going to get in to how to set up BitBucket Pipelines from the ground up, I’ve covered that at length in the previous article here, and also in more depth previously here if you need to see that.
Now that we know how all of this needs to run, we can represent it in our bitbucket-pipelines.yml as:
#--bitbucket-pipelines.yml
image: hashicorp/terraform:0.14.5
pipelines:
branches:
master:
- step:
name: Speculative Plan
script:
- mkdir -p terraform/plan
- terraform init -backend-config="access_key=$AWS_ACCESS_KEY_ID" -backend-config="secret_key=$AWS_SECRET_ACCESS_KEY"
- terraform workspace select $BITBUCKET_BRANCH || terraform workspace new $BITBUCKET_BRANCH
- terraform validate
- terraform plan -out plan/$BITBUCKET_COMMIT.plan
artifacts:
- terraform/plan/**
- terraform/.terraform/**
- step:
name: Apply Configuration
trigger: manual
script:
- cd terraform
- terraform apply -input=false -auto-approve plan/$BITBUCKET_COMMIT.planThe commands we see here are now broken in to two steps, with the plan and apply being carried out as separate steps. Now on a commit to any branch:
- A temporary directory is created inside our build container’s working directory named plan.
- A Terraform workspace is selected (if it exists) or created (if it doesn’t exist). The workspace will be named for the branch the pipeline is executing on.
- Terraform is initialised and the configuration validated.
- A speculative plan is output to a file with the commit ID that triggered the pipeline in the plan directory.
- The artifacts key is used to temporarily upload the entire contents of the .terraform and plan directories. Artifacts are carried between steps (and therefore between build agent containers). This means terraform does not need to be re-initialised and our single-use speculative plan is available for use in an apply.
- On running the manual trigger, our speculative plan is used as the basis for an apply.
The automation pipeline can now be seen to have a Continuous Delivery phase when the first step ends as we can be confident that the configuration has validated and we will be able to see it’s projected changed via the speculative plan generated in the console:
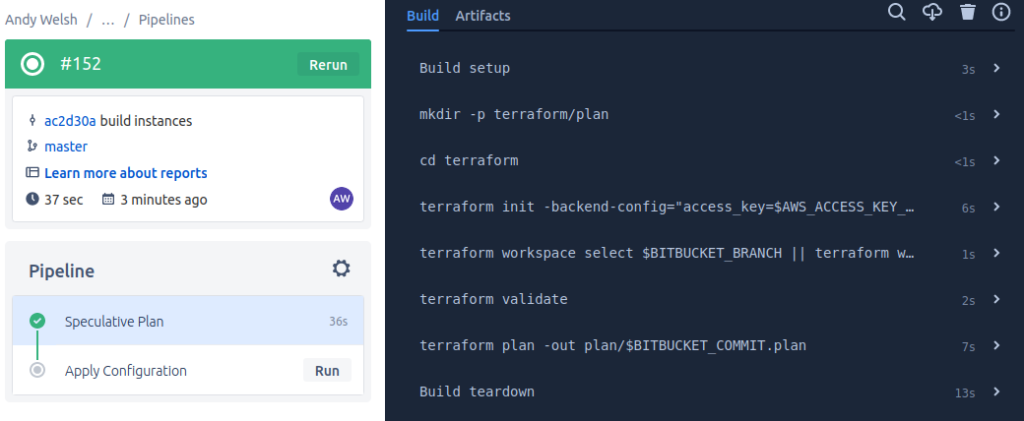
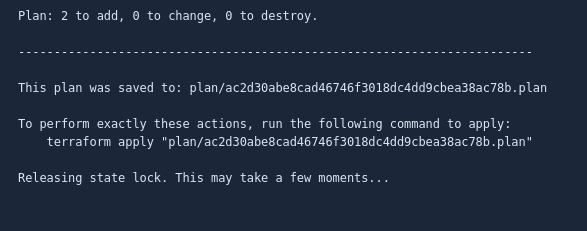
Assuming that this is all good, we can now pull the trigger on a manual run to apply our changes and our configuration will be applied:
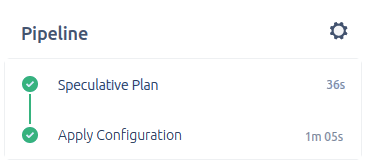
Conclusion
Once upon a time I would have made the argument that things should be entirely automated or no cigar. We’re often faced with the reality that these systems can fail us and the biggest risk of failure is human error, when a quick review is all that’s needed to prevent catastrophe I think we can accept the trade off in most cases.
Of course, none of that is going to save you if you don’t read the output in the console, so always scrutinise your plans, they’ll save you one day. I heard someone say recently that they eventually stopped reading Pull Requests because everyone just clicks approve anyway…what’s critical is that the approval gate is only as good as your desire to read what’s in it. The best warnings in the world won’t help if nobody ever looks at them!
You also need to add “.terraform.lock.hcl” in the artifact section. Otherwise the next step may throw “Inconsistent dependency lock file” error.
I can’t say I have ever encountered this or understand why it would be the case, I’ve run Terraform this way for a long time and have never seen this error being thrown so I would be tempted to think it was an implementation issue. Artifacts are output files whereas the .terraform.lock.hcl file is lock file for provider versions. Could you maybe suggest why adding the file to artifacts solves anything?